




What is Deep Learning and Why is it Important?
 5 Minute read
5 Minute read

Image Processing (IP) is a type of computer technology that allows us to process, analyse, and extract information from images.
It's one of the fastest-growing technologies, but it's changed dramatically over time. Today, image processing is used by a variety of businesses and organisations for a variety of purposes, including visualisation, image information extraction, pattern recognition, classification, segmentation, and more.
Analogue and digital image processing are the two main types of image processing. The analogue IP approach is used to process hard copies such as scanned photos and prints, with the outputs often being images. The Digital IP, on the other hand, is used to manipulate digital images using computers; the outputs are usually image-related information, such as data on features, attributes, bounding boxes, or masks.
Here are a few examples of common use cases for machine learning image processing techniques :
- Medical Imaging / Visualization : Assist medical practitioners in more quickly interpreting medical imaging and diagnosing irregularities.
- Law Enforcement & Security : Aid in surveillance and biometric authentication for law enforcement and security.
- Self-Driving Technology : Self-driving technology can help with object detection and replicating human visual cues and interactions.
- Gaming : Improving game experiences in augmented reality and virtual reality.
- Image Restoration & Sharpening : Enhance image quality or apply popular filters, for example.
- Pattern Recognition : Classify and recognise objects/patterns in photographs, as well as comprehend contextual information.
- Image Retrieval : Recognize images for faster image retrieval from vast datasets.
Working of Machine Learning Image Processing
To begin, ML algorithms require a large amount of high-quality data in order to learn and anticipate extremely accurate outcomes. As a result, we'll need to make sure the images are well-processed, annotated, and generic enough to be used in machine learning image processing. This is where Computer Vision (CV) comes in; it's a field concerned with machines' ability to comprehend image data. We can analyse, load, transform, and modify photos with CV to create a perfect dataset for the machine learning algorithm.
- All of the images are being converted to the same format.
- Cropping out the parts of an image that aren't needed.
- They are converted into numbers so that algorithms can learn from them (array of numbers).
An input image is seen by computers as an array of pixels, with the number of pixels varying depending on the image resolution. It will see height * width * dimension based on the image resolution. An image of a 6 × 6 x 3 array of an RGB matrix (3 refers to RGB values) and a 4 x 4 x 1 array of a grayscale image, for example.
These features (processed data) are then employed in the next phase, which involves selecting and developing a machine-learning algorithm to classify unknown feature vectors from a large library of feature vectors with known classifications. We'll need to pick a good algorithm for this; some of the most common ones include Bayesian Nets, Decision Trees, Genetic Algorithms, Nearest Neighbors, and Neural Nets, among others.
Libraries and Frameworks for Machine Learning Image Processing
-
OpenCV-Python :OpenCV-Python is a Python bindings library forsolving computer vision challenges. It's straightforward and simple to useFeatures :
- Huge library of image processing algorithms
- Open Source + Great Community
- Works on both images and videos
- Java API Extension
- Works with GPUs
- Cross-Platform
-
Tensorflow :Tensorflow is a prominent end-to-end machine learning programming framework created by Google.Features :
- Wide range of ML, NN Algorithms
- Open Source + Great Community
- Work on multiple parallel processors
- GPU Configured
- Cross-Platform
-
PyTorch :One of the most popular neural network frameworks for researchers is PyTorch (by Facebook). When compared to other ML libraries, it is more pythonic.Features :
- Distribution Training
- Cloud Support
- Open Source + Great Community
- Works with GPUs
- Production Ready
-
Caffe :Caffe is a deep learning framework that focuses on expression, speed, and modularity. Berkeley AI Research (BAIR) and community collaborators are working on it.Features :
- Open Source + Great Community
- C++ Based
- Expressive Architecture
- Easy and Faster Execution
-
EmguCV :EmguCV is a cross-platform CV editor. The OpenCV image processing library is wrapped in a Net wrapper.Features :
- Open Source and Cross-Platform
- Working with .NET compatible languages – C #, VB, VC ++, IronPython, etc.
- Compatible with Visual Studio, Xamarin Studio and Unity
-
MATLAB Image Processing Toolbox :Image Processing Toolbox programmes from MATLAB allow you to automate standard image processing procedures. You can segment picture data interactively, compare image registration algorithms, and handle big data sets in batches.Features :
- Wide range of Deep Learning Image Processing Techniques
- CUDA Enabled
- 3D Image Processing Workflows
-
WebGazer :WebGrazer is a JS-based eye tracking framework that uses regular webcams to infer online visitors' eye-gaze locations on a page in real-time.Features :
- Multiple gaze prediction models
- Continually supported and Open Source for 4+ years
- No special hardware; WebGazer.js uses your webcam
-
Apache Marvin-AI :Marvin-AI is an open-source AI platform that enables the delivery of complicated solutions with a high-scale, low-latency, language-agnostic, and standardised architecture while simplifying exploitation and modelling.Features :
- Open Source and Well documented
- Easy to use CLI
- Multi-threaded image processing
-
MIScnn :MIScnn is a deep-learning-based open-source system for medical image segmentation.Features :
- Open Source and Well Documented
- Creation of segmentation pipelines
- Decently pre-processing and post-processing tools
- CNN Implementation
-
Kornia :Kornia is an open-source differentiable computer vision library built on PyTorch.Features :
- Rich and low-level image processing techniques
- Open Source and Great Community
- Differentiable programming for large applications
- Production Ready, JIT Enabled
-
VXL :VXL (the Vision-something-Libraries) is a set of C++ libraries aimed towards computer vision research and development.Features :
- Open Source
- 3D Image Processing Workflows
- Designing a graphical user interface

Deep Learning Image Processing
- Convolutional Layer
- Pooling Layer
- Fully Connected Layer
Convolutional layer
The convolutional layer is the brains of CNNs; it handles the majority of the work in detecting the characteristics in a given image. Then, in the convolution layer, we take square blocks of the input image of a random size and use the dot product with the filter (random filter size). The convolution layer output will be high if the two matrices (the patch and the filter) have high values in the same places (which gives the bright side of the image). It will be low if they don't (the dark side of the image). In this method, we can tell whether the pixel pattern in the underlying image matches the pixel pattern given by our filter based on a single value of the dot product output.
Pooling Layer
We have many feature maps when we use the convolutional layers to detect the features. When the convolutional operation is applied between the input image and the filter, these feature maps appear. As a result, we'll need another procedure to downsample the image. As a result, the "pooling" technique is used to minimise the pixel values in the arrays, making the learning process easier for the network. They operate independently on each depth slice of the input and spatially resize it using two separate operations :
Max Pooling
returns the largest value from the picture covered by the Kernel's array.
Average Pooling
Fully Connected Layer (FC) :
The fully connected layer (FC) works with a flattened input, meaning that each input is connected to all neurons. These are typically employed at the network's end to connect the hidden layers to the output layer, which aids in class score optimization.
What is a deep neural network, and how does it work?
A deep neural network (DNN), or deep net for short, is a neural network with a certain amount of complexity, usually at least two layers. Deep nets use advanced math modelling to process data in complex ways.
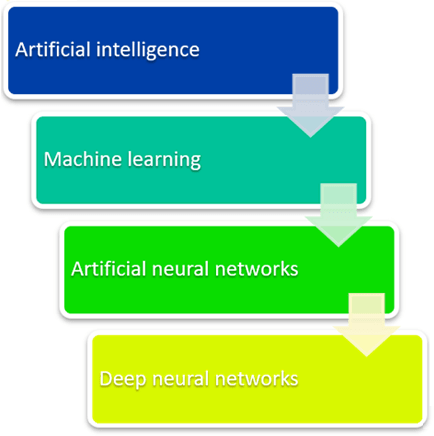
Machine learning had to be built first. ML is a framework for automating (through algorithms) statistical models, such as linear regression models, in order to improve prediction accuracy. A single model that makes predictions about something is referred to as a model. Those forecasts are reasonably accurate. A learning model (machine learning) takes all of its incorrect predictions and adjusts the weights within the model to develop a model that makes fewer errors.
Artificial neural networks arose from the learning component of the modelling process. The hidden layer is used by ANNs to store and evaluate how important each of the inputs is to the output. The hidden layer retains information about the relevance of inputs and forms links between the importance of different combinations of inputs.
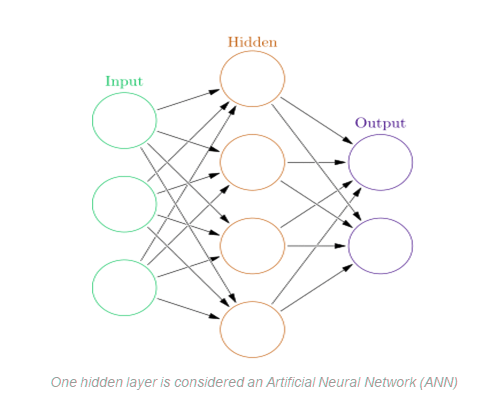
Deep neural networks, on the other hand, make use of the ANN component. They argue that if this improves a model so well—because each node in the hidden layer creates both associations and grades the value of the input in determining the output—then why not stack more and more of these on top of each other to get even more benefit from the hidden layer?
As a result, there are several hidden levels in the deep net. A model's layers are said to be 'deep' if they are numerous layers deep.
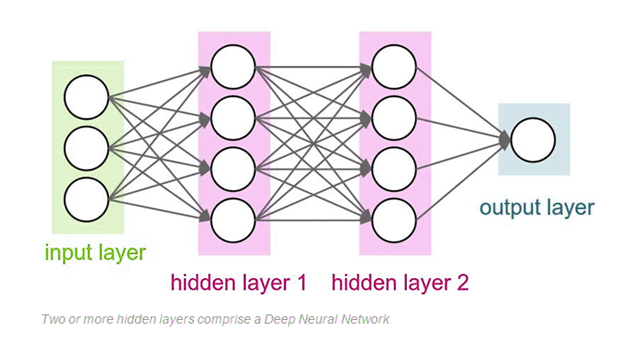
Neural Network architecture
Deep convolutional neural networks can be thought of as layers of neurons, each of which can be classified into distinct categories based on its connectivity structure. Convolutional, pooling, and fully linked layers are the most prevalent. In general, each layer is associated with a unique set of parameters, which together make up the network's full collection of connection weights and biases. Hyperparameters are the parameters that are employed particularly during the training method.
The numerous layer types, each with its own set of parameters, as well as the hyperparameters and their impact on training quality and speed, make selecting a high-performing architecture difficult. As a result, prior empirical evidence (i.e., the performance of previously reported designs on structurally similar issues) as well as domain expertise and insight into the nature of the challenge at hand are critical in guiding design decisions.
Convolutional blocks are the building blocks of the network architecture we built. With the exception of the amount of kernels, every convolutional block has the identical hyperparameters and is made up of two sets of convolutional layers, batch normalisation, and rectified linear unit activation. A max-pooling procedure is used after a convolutional block to minimise the dimensionality of the modified input.
The final design consists of five convolutional blocks in a row and max-pooling pairings. With the exception of the last layer, the number of filters is doubled after each pooling layer. The output of the last pooling layer is flattened and processed by three fully connected layers of 4096 neurons, followed by an 83-output soft-max output layer. Except for the final output, dropout is applied to all fully connected layers. A Gaussian distribution is used to generate the initial values for the weights and biases.
Deep learning models must be trained (such as neural networks)
To create an ML model that can forecast customer churn, for example, data scientists must first define the input features (problem attributes) the model will take into account when predicting a result. If we used feature engineering to build a deep learning model to recognise the difference between a dog and a cat... Imagine compiling data on the characteristics of billions of cats and dogs on the earth. We can't build precise features that will work for every potential image while taking into account issues like viewpoint-dependent object variability, background clutter, lighting conditions, and image deformation. There should be another way, and owing to the nature of neural networks, there is.
The black box problem : Improving accuracy
Deep nets improve the accuracy of a model's performance. They enable a model to accept a collection of inputs and produce a result. Copying and pasting a line of code for each layer is all it takes to use a deep net. It makes no difference which machine learning platform you use; telling the model to use two or 2,000 nodes in each layer is as easy as typing the numbers 2 or 2000.
However, adopting deep nets raises a question : how do these models make decisions? The explanation is the ability of a model is greatly diminished when these simple tools are used.
The Deep Net allows a model to develop its own generalisations and then store them in a hidden layer called the black box. It's difficult to investigate the black box. Even if the values in the black box are known, there is no context through which to understand them.
Apps for recognising works of art using Neural Networks
Magnus is an app that uses picture recognition to help art collectors and lovers "navigate the art jungle." When a user takes a photo of a work of art, the app displays information such as the creator, title, year of production, size, material, and, most crucially, the current and historical price. The app also includes a map containing galleries, museums, and auctions, as well as artworks that are currently on display.
Magnus gathers information from a database of over 10 million photographs of artworks, as well as crowdsourced information about pieces and pricing. Magnus claims on the app's Apple Store page that Leonardo DiCaprio invested in it.
Apps like Smartify can satiate museum visitors' thirst for knowledge. Smartify is a museum guide that can be used at a variety of locations around the world, including the Metropolitan Museum of Art in New York, the Smithsonian National Portrait Gallery in Washington, DC, the Louvre in Paris, Amsterdam's Rijksmuseum, the Royal Academy of Arts in London, and the State Hermitage Museum in Saint Petersburg, among others.
Conclusion
